浅谈作为前端开发对二叉树遍历的理解
二叉树是一种计算机基础数据结构,最近在写树组件的时候有用到了这个基本知识,这里总结一下。
1. 引
它的实际使用场景非常广泛。以下是一些常见的二叉树应用场景:
- 文件系统:文件系统的目录结构可以使用二叉树表示,每个节点代表一个文件或目录,通过左子节点和右子节点连接形成层级结构。
- 数据库索引:数据库索引通常使用二叉树实现,比如二叉搜索树(BST)用于快速搜索和检索数据。
- 表达式解析和计算:二叉树可以用于解析和计算表达式,如数学表达式. 布尔表达式等。
- 图像处理:在图像处理中,二叉树常用于图像压缩算法(如哈夫曼编码)和图像渐进式加载。
- 路由算法:在网络路由中,二叉树可以用于构建路由表,帮助确定数据包的传输路径。
- 解析树:二叉树可以用于构建解析树,用于解析和理解自然语言. 编程语言等结构化数据。
- 人工智能和决策树:决策树是一种特殊的二叉树,常用于人工智能中的分类和决策问题。
- 堆和优先队列:二叉堆是一种特殊的二叉树结构,用于实现优先队列和堆排序算法。
- 编译器和解释器:在编译器和解释器中,二叉树常用于语法分析和构建抽象语法树(AST)。
- 数据压缩:二叉树常用于数据压缩算法,如霍夫曼编码(Huffman Coding),通过树的构建和路径编码来实现数据的高效压缩和解压缩。
- 线段树:线段树是一种特殊的二叉树,用于处理区间查询问题,如区间最小值. 区间和等。
- 索引结构:二叉树可用于构建各种索引结构,如B树和B+树,用于快速的数据库查询和索引操作。
- 线索二叉树:线索二叉树是一种优化的二叉树结构,通过添加额外的线索信息,可以快速进行中序遍历. 前序遍历等操作。
- 缓存实现:LRU Cache(最近最少使用缓存)常使用双向链表和二叉树(如红黑树)相结合的方式实现,以快速插入. 删除和查找最近使用的数据。
二叉树一个重要的算法就是他的的遍历,在AST编译器开发. 路由导航. 文件系统等等业务场景中都在广泛的使用。
2. 构建一个二叉树
二叉树有一个根节点,所有的父节点最多只能有两个孩子。我们可以构造一个二叉树如下:
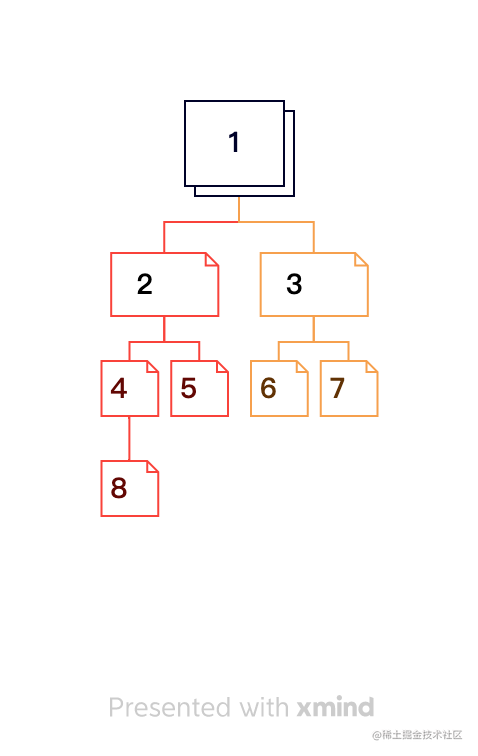
代码结构如下:
const tree = {
name: 1,
children: [
{
name: 2,
children: [
{
name: 4,
children: [{ name: 8 }],
},
{ name: 5 },
],
},
{
name: 3,
children: [{ name: 6 }, { name: 7 }],
},
],
};
接下来结合图形,用代码来实现一下他的遍历:
3. 遍历
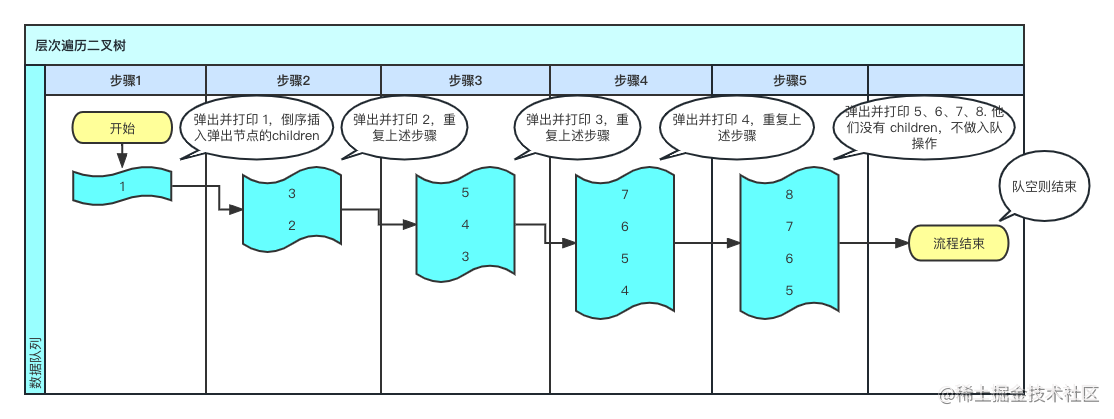
层次遍历
按照层级遍历
算法思路:
- 建立一个队列,从根节点开始,将其子节点的子节点从左至右入队
- 遍历队列并出队,重复第二步后半部分
- 队列为空则遍历结束
function traverse(node) {
if (!node) {
return;
}
const queue = [];
queue.unshift(node);
while (queue.length > 0) {
const printNode = queue.pop();
console.log(printNode.name);
if (printNode.children && printNode.children.length > 0) {
queue.unshift(...printNode.children.slice().reverse());
}
}
}
先序遍历
递归实现
- 从根节点开始
- 将左右节点当做子树,先遍历左节点,再遍历右节点
- 直到当前节点没有子节点为止
function preOrderTraverse(root) {
if (root != null) {
const children = root.children || [];
console.log(root.name);
preOrderTraverse(children[0]);
preOrderTraverse(children[1]);
}
}
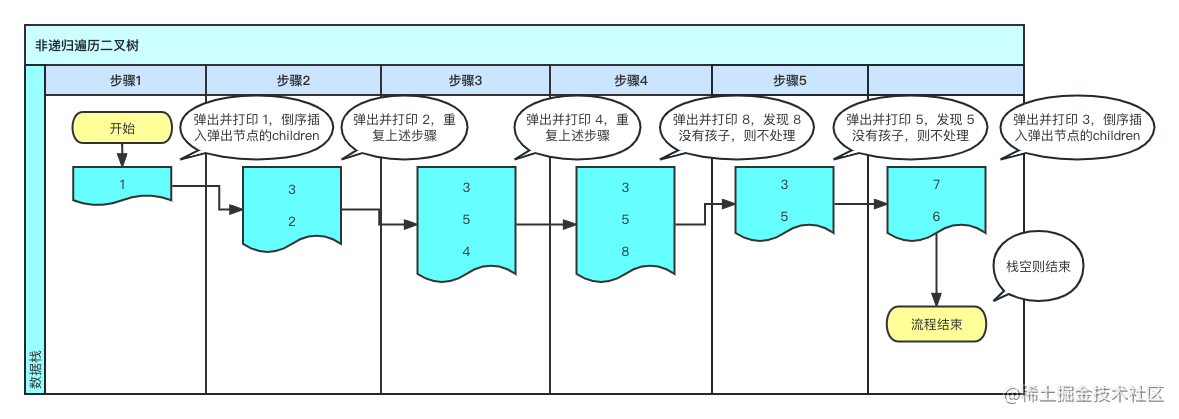
非递归实现
- 建立一个栈,入栈根节点
- 出栈当前节点,将当前节点子节点集合逆向入栈
- 重复第二步,直到栈空
function preOrderTraverse(node) {
if (!node) return;
const track = [];
track.push(node);
while (track.length > 0) {
const node = track.pop();
console.log(node.name);
const children = node.children;
if (children && children.length > 0) {
track.push(...children.reverse());
}
}
}
思考:学会了先序遍历,相信你应该能够很容易的写出后序遍历的实现!
中序遍历
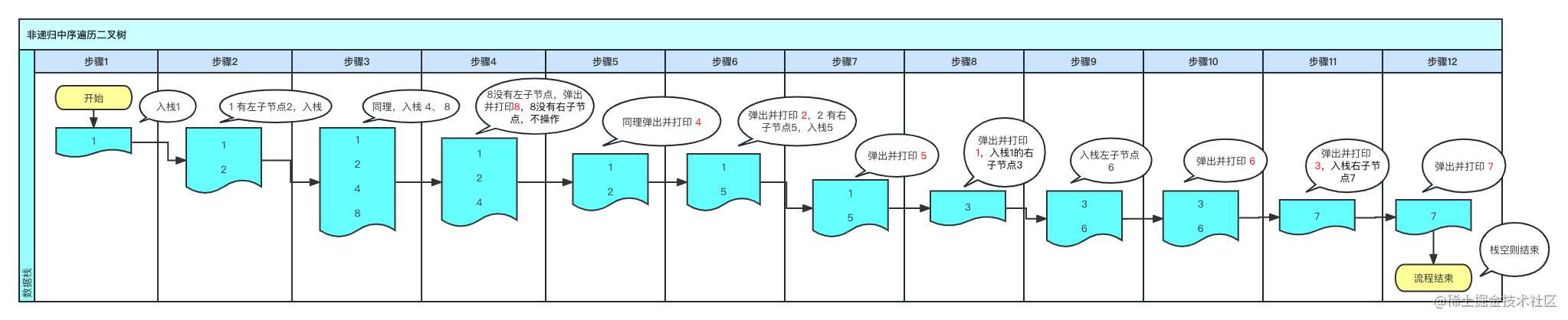
非递归实现
- 建立一个栈,入栈根节点
- 若有左子节点,则入栈,直到没有左子节点时出栈栈顶元素并打印,入栈栈顶元素的右子节点
- 重复第二步,直到没有可用元素且栈空为止
function middleOrderTraverse(node) {
if (!node) return;
const stack = [];
let currentNode = node;
while (currentNode || stack.length > 0) {
if (currentNode) {
stack.push(currentNode);
currentNode =
currentNode && currentNode.children ? currentNode.children[0] : null;
} else {
const poped = stack.pop();
console.log(poped.name);
currentNode = poped.children ? poped.children[1] : null;
}
}
}
链表实现
链表不适合做广度优先遍历,下面示意图中,深度优先会非常的方便。我们拿 react fiber 的结构来举例。
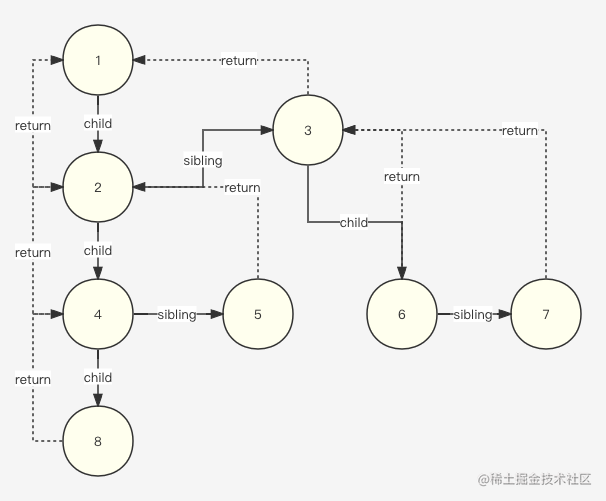
- 遍历思路:从根节点开始,以此遍历每一个经过的节点的 child 和 sibling
伪代码实现:
function linkedListTraverse(root) {
let wip = root;
while (wip) {
console.log(wip);
if (wip.child) {
temp = wip.child;
wip.child = null; // 遍历过就剔除
wip = temp;
continue;
}
if (wip.sibling) {
temp = wip.sibling;
wip.sibling = null; // 遍历过就剔除
wip = temp;
continue;
}
wip = wip.return;
}
}